Parsing and executing calculations
Years ago I setup an algorithm using a conversion to Reverse Polish Notation to store and execute calculation code. Later, facing the thought to implement it in Java that is strictly object oriented, I got the idea of the object oriented version. As I didn't plan to make it public, the code is not perfect, but it might be useful to someone. So here it is.
For some applications, the functionality where the user may type in a mathematical relation that must be read in and executed or a graphical curve stored in electronic form might be useful. I here provide two solutions :
-
the first converts the input text in Reverse Polish Notation. In this notation the arguments are put first and the operations come up in the order in which they are executed. Therefore this notation does not need any parentheses. This notation is then stored in a series of calls to routines that take their arguments from a stack and put their result on that same stack to make it available to the next operators/functions. This is the way the Hewlet-Packard calculators work.
This technique only uses pure C code and no object orientation used at all. A more detailed description is here Conversion
-
the second uses an object oriented technique. It uses a set of classes derived from a common parent. Each operator or function will be implemented by an instance of the appropriate class (constant value, unary or binary operator, arithmetic function ...) that has references to the global parent class as argument(s). The last executed operation/function is at the trunc of the tree, and the operations that are executed first are the leaves of the tree.
Storage of calculations in Reverse Polish way
For more details on the storage of the mathematical relations in RPN manner see Calculations.pdf.
An overview of the software is given in read me.
A detailed description of the concept
A description of the source code files is given in file descriptions.
The format of the read in text files is in Text2.txt.
The source code files are in directory Source files:
* : files used only for MacOS version.
The source files to be compiled are:
Calculs.c, Parser.c, Test.c (if macro TEST is defined), main.c, UX_StdLib.c (only under MacOS if the user interface is included by defining macro MAC_UI).
(Display.c is included in main.c so does not need to be specifically compiled).
In order to convert floating point values from and to text, MacOS system provides toolbox routines FormatX2Str (ExtendedToString) and FormatStr2X (StringToExtended).
Routine FormatX2Str is used in in all versions in source file Display.c to print outputs in the upper part of the main window, and when compiler switch USE_FORMATX2STR is defined also in the Debug routine in file Calculs.c that generates the view of the code in the additional right window and in the implementation of the printf in file UX_StdLib.c. This last routine is used to write the output in the lower part of the main window used as a console.
In the first case it works fine, but in the printf implementation, the first conversion produces the right result, but the following ones not when using the Symantec C++ 8.5 IDE. With the CodeWarrior 6.0 IDE the results are a little different. For a detailed description see Problems with FormatX2Str later. I have so far not found out what's wrong. Maybe someone will....
Please note that on non english systems, you will have to set the decimal separator to '.' in the Numbers control panel when using the basic version. Internationalization is implemented in the special version of the application.
Version using own conversion code:
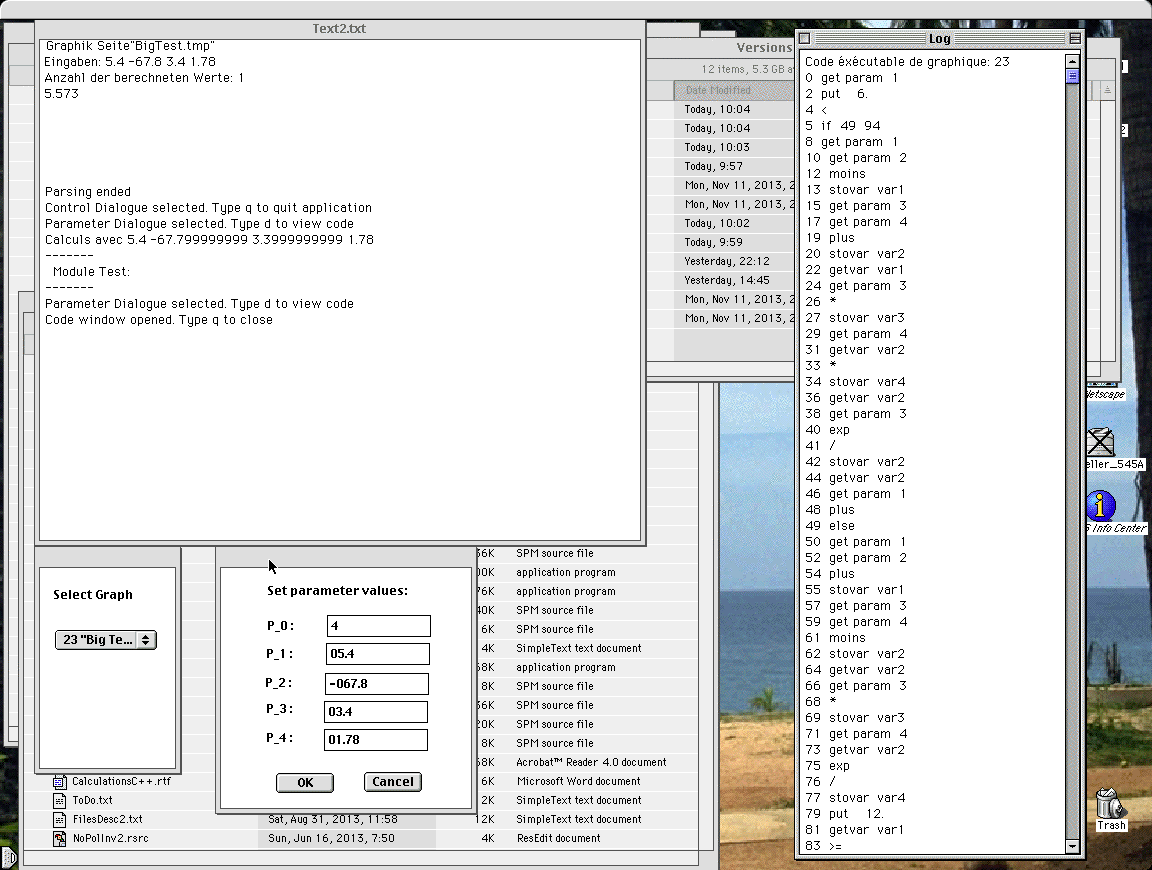 Version using FormatX2Str:
Version using FormatX2Str:

The compiled applications under Symantec C++ for MacOS are provided with the source in the archives linked below :
The name starts with SC_ as they are compiled with Symantec C++.
- SC_RPN.exe : basic version that does not use FormatX2Str Toolbox routine in the UX standard routines (UX_StdLib.c) and in the display of the stored code (Calculs.c). The Toolbox routine is always used in code in Display.c for all versions. In order to run this version you have to set the point '.' as decimal separator in the Numbers control panel!
- SC_RPN_ITL.exe : version that does not use FormatX2Str (in UX_StdLib.c and Calculs.c) but gets the decimal separator from the international tables (set in Numbers control panel).
- SC_RPN_Test.exe : version including the test code as well as the internationalization switch.
- SC_RPNFmtX2Str_Test.exe : version including the test code as well as the internationalization switch. It also uses routine FormatX2Str for the console output (low part of main window) as well as the display of the stored code (additional right window).
The test versions contains additional code that calculates the expected value corresponding to the code selected. The comparison is done without a tolerance value, therefore the message might indicate a discrepance but twice the same value. Pay attention in the case of the SC_RPNFmtX2Str_Test version, that the second value is not output correctly! This may be misleading.
The source code to be read in is provided in 2 versions, once with the '.' (point) as decimal separator and once with the ',' (comma) as decimal separator. Rename the necessary one to Text2.txt to use the application.
Here you find a all packed into a Stuffit archive: RPN .sit Archive RPN .sea Archive
Little cleanup and an optimization as well as improvement of error handling are still planned.
The version compiled with CodeWarrior are named the same way starting with CW_ and provided here RPNCWadapt
Storage of calculations in object oriented way
For more details on the storage of the mathematical relations in Object Oriented manner see CalculationsC++.pdf.
An overview of the software is given in read me.
A description of the source code files is given in file descriptions.
The format of the read in text files is in Text2.txt.
The source code files are in directory Source files:
* : files used only for MacOS version.
The source files to be compiled are:
OperandClasses.cpp, Parser.cpp, Parser.cp, Test.cp (if macro TEST is defined), main.cp, UX_StdLib.cp (only under MacOS if the user interface is included by defining macro MAC_UI).
(Display.c is included in main.c so does not need to be specifically compiled).
As for the postfix version, in order to convert floating point values from and to text I used the MacOS system provided toolbox routines FormatX2Str (ExtendedToString) and FormatStr2X (StringToExtended).
Routine FormatX2Str is used in file Display.c to print outputs in the upper part of the main window, and when compiler switch USE_FORMATX2STR is defined also in the Print method of class ConstOperand in file OperandClasses.cpp to generate the view of the code in the additional right window and in the implementation of the printf in file UX_StdLib.cp. This last routine is used to write the output in the lower part of the main window used as a console.
In the first 2 cases it works fine, but in the printf implementation, the first conversion produces the right result, but the following ones not when using the Symantec C++ 8.5 IDE. With the CodeWarrior 6.0 IDE the results are a little different. For a detailed description see Problems with FormatX2Str later.
As for the reverse polish version check you have to set the decimal separator to '.' in the Numbers control panel when using the basic version, or use the internationalized version.
The compiled applications under Symantec C++ for MacOS are provided with the source in the archives linked below :
The name starts with SC_ as they are compiled with Symantec C++.
- SC_C++.exe : basic version that does not use FormatX2Str Toolbox routine in the UX standard routines (UX_StdLib.c) and in the display of the stored code (OperandClasses.cpp). The Toolbox routine is always used in code in Display.c for all versions. In order to run this version you have to set the point '.' as decimal separator in the Numbers control panel!
- SC_C++_ITL.exe : version that does not use FormatX2Str (in UX_StdLib.cp and OperandClasses.cpp) but gets the decimal separator from the international tables (set in Numbers control panel).
- SC_C++_Test.exe : version including the test code as well as the internationalization switch.
- SC_C++FmtX2Str_Test.exe : version including the test code as well as the internationalization switch. It also uses routine FormatX2Str for the console output (low part of main window) as well as the display of the stored code (additional right window).
The test versions contains additional code that calculates the expected value corresponding to the code selected. The comparison is done without a tolerance value, therefore the message might indicate a discrepance but twice the same value. Pay attention in the case of the SC_C++FmtX2Str_Test version, that the second value is not output correctly! This may be misleading.
Here you find a all packed into a Stuffit archive: Object .sit Archive Object .sea Archive
The version compiled with CodeWarrior are named the same way and provided here ObjectCWadapt
The user interface
Two main versions are provided.
Depending on the definition of the compiler switches SPRACHE and MAC_UI different user interfaces are provided.
-
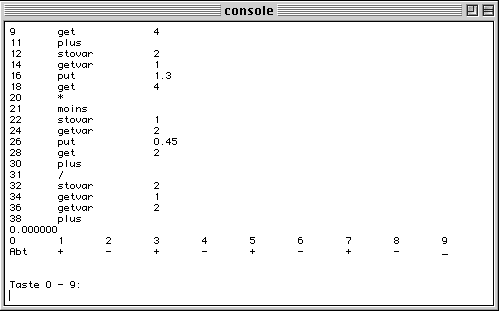
If none is defined, all is printed in a console. First the identification number of the formula has to be selected (-1 to quit). The stored code is then listed in the console. The the keys 1 to 8 act as -/+ keys to decrement/increment the parameter values p_1 to p_4. Each modification launches an execution of the selected formulas.
-
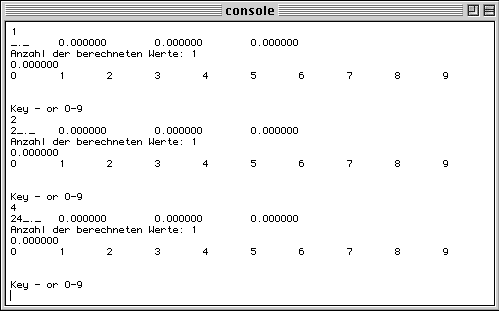
If SPRACHE is defined, then all is still printed in a console, but the setting of the parameter values follows another scheme. First the parameter has to be selected with the keys 1 to 4. Then its value is set: first the integer part with the keys 0-9 and -. Then typing in . switches to the fractional part set with keys 0 to 9.
Typing in = launches the execution of the selected calculation(s).

-
If MAC_UI is defined, a minimal MacOS Classic user interface is implemented.
See interface description
Small description of the console interface:
At start after reading in the text file, you have to select the calculation to be executed by typing in its ID number. The stored code is then first displayed.
Then depending on if the compiler switch SPRACHE, two ways for setting the values of the input parameters p_<1 .. 4> are provided:
-
if the compiler switch is not defined, the values are set with keys 1 to 8 that act as + and - incrementing/decrementing the values of p_1 to p_4 by the values given in the RESOLUTIONS field. Each time a value is changed, the calculation is executed and the result displayed.
-
if the compiler switch is defined, the values are set another way: first the parameter to be set has to be selected with keys 1 to 4. Its value is then dismayed as _._. With the keys - and 0 to 9 the integer part can be set. Typing . switched to the fractionary part that can be set with keys 0 to 9. Once key = is typed, the calculation is executed and the result displayed.
Typing in 0 or 9 will quit the selected calculation to switch to another calculation.
Small description of the MacOS user interface:
At start 3 windows are opened:
The only difference between the Postfix and the Object Oriented implementations is the display of the stored code.
-
- at the top the main window in which the results of the selected calculation are printed.
Messages are printed in the lower part of this main window used as console.
-
- the lower left window presents a popup menu listing the formulas read out of the text file. Here select the identification number/title of the formula.
When this window is selected, typing in 'q' will quit the application.
-
- the lower right window is provided to set the value for the up to 4 input parameters. The first field hods the value from the PARAMETER field.
When this window is selected, typing in 'd' will open a new window in which the stored code is dispelled (in reverse polish notation). You first have to type in 'q' to quit it to return to the other windows. The content is then copied to the clipboard when the application is quit (useful when debugging).
Please note that internationalization is only implementd in the appropriate version. If the output of the parameter values you set in the lower right window seems to ignore the '.' and you just get integers, just set the decimal separator in the Numbers control panel to '.' and not the ',' that is set per default on German or French systems.
In newer versions, the decimal separator is read out from the international resources (conpiler switch USE_ITL).
The output in the lower part of the main window also contains some information dealing with the user actions to be done.
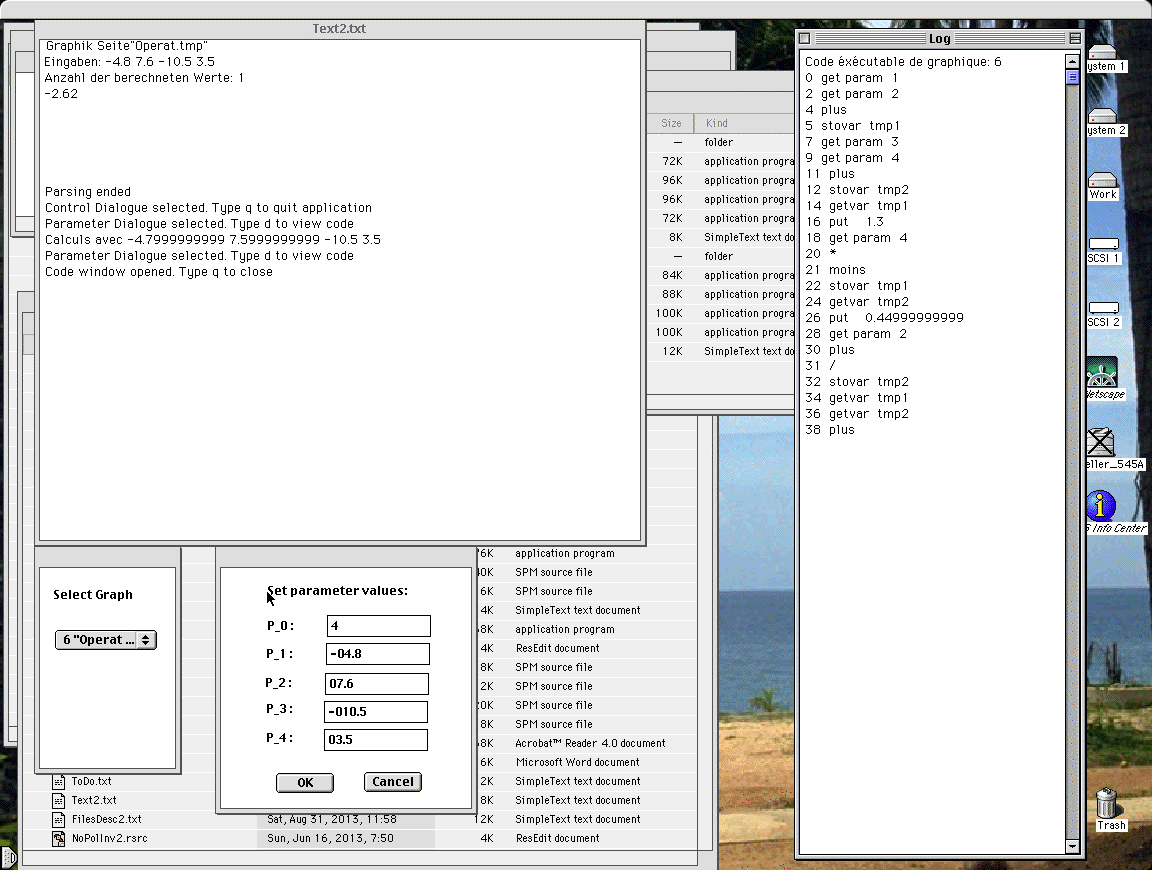
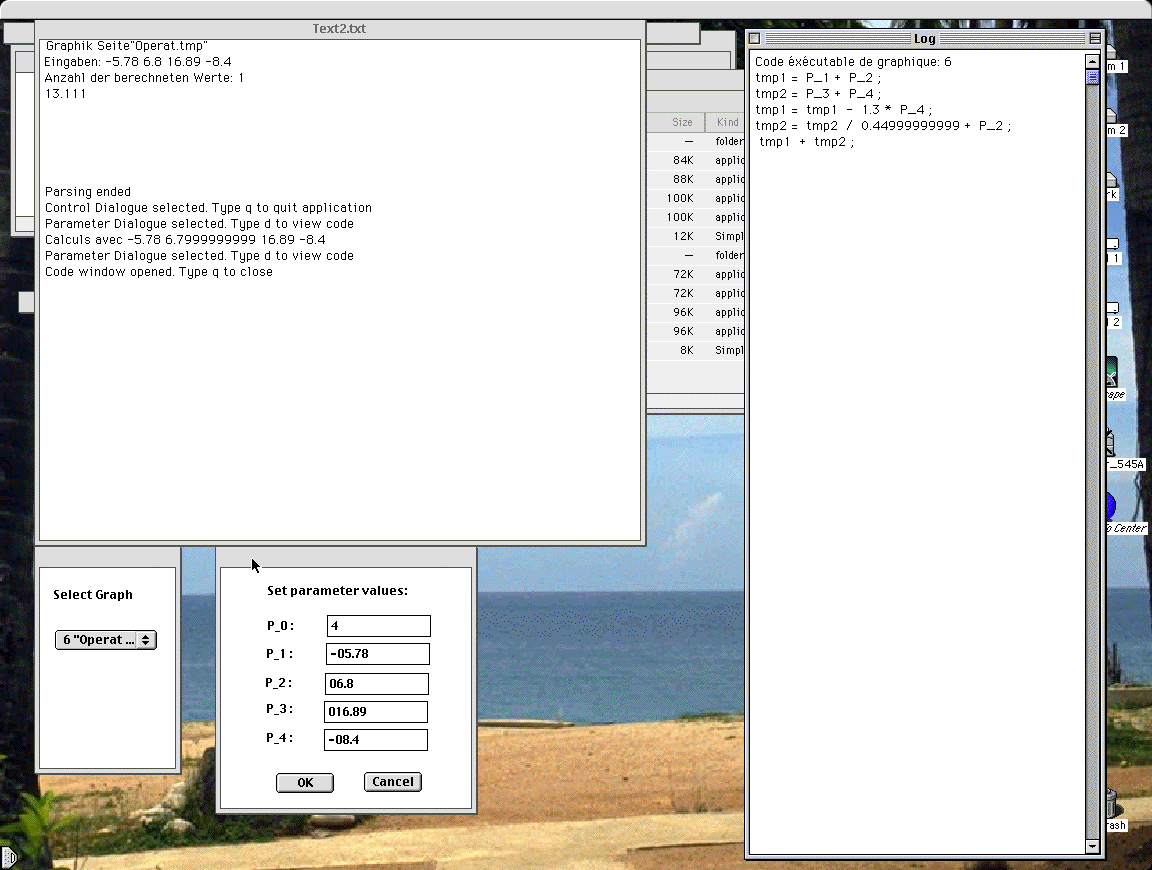
Just before release I noticed a bug in the handling of the edit boxes in the lower right dialog. Once the typed in text reaches 9 characters, and another edit box is selected, it is not possible anymore to modify its content. Some debugging showed that the contrlRect data gets damaged. This is temporary solved by a limitation of the string length.
The event handling has to be reworked (especially implemented using DialogSelect).
Software description
Reverse Polish or Postfix Notation
In this notation, the operands are put first followed by the corresponding operators in decreasing priority order. This notation does therefore not need parentheses.
The software parses the source code from left to right. When reading in an arithmetic or boolean expression from the input code, the operands have to be pushed before she operators that act on them and the operators with higher priority put before the ones with lower priority. This is achieved with a stack on which each operator is pushed after taking off the operators with higher priority fro the stack to push them to the output code.
The parentheses have been defined as operator with lowest priority so when reaching a closing parentheses ) all operators up the the opening parentheses ( are taken off the stack and transferred to the output code.
Object oriented version
For each control flow structure (if else, while for structures) and each code sequence terminated by a ;, an instance of the corresponding class defined in OperandClasses.h/cpp is generated.
As the whole output code and the branches of the control flow structures may have several arithmetic expressions separated by ;, the whole source code as well as each branch in the classes for the control structures are an array of references to the top parent class.
When reading in an arithmetic of boolean expression, the software is structured in imbricated function calls. The routines that read and generate the objects for the higher priority operators are called from the routines that handle the operators with lower priority. The routines return a reference to a structure of objects that implement the code to execute those operators, so that the calling routine can use it as its operand.
For example, the routine that parses and generates the objects to implement the additions and subtractions calls the routine that parses the multiplications and divisions that will return the result as argument for the additions and subtractions.
Problems to be mentioned:
When using the CodeWarrior 6.0 IDE, the problem with the usage of the routine FormatX2Str (ExtendedToString) is somewhat different from Symantec IDE. This routine is always used in the code printing the text at the top of the main window (Display.c) but only if compiler define USE_FORMATX2STR is set in the lower part of the main window (UX_StdLib.c/cp) used as a console as well as in the additional right window displaying the stored code (Calculs.c/OperandClasses.cpp).
The toolbox routine FormatStr2X (StringToExtended) is used in the conversion of the parameter values in the edit boxes of the bottom right window if USE_FORMATX2STR is defined. This conversion works fine.
For the first routine, following problems must be considered:
- for the applications compiled with Symantec C++ 8.5 IDE, only the code generating the console output (lower part of main window) is affected by the problem (UX_StdLib.c) :
the first conversion of every printf call give the right result, the following do not provide the right string.
-
for the applications compiled with CodeWarrior 6.0 IDE:
- in the case of the postfix applications the code for the console output causes trouble when using the toolbox routine. The text always outputs twice the value of the actual source value, and also the code generating the text view of the stored code: after application launch, the first conversion is right, the others do not provide the right string.
- for the object oriented versions compiled with the C++ compiler, the code generating the output in the top of the main window (Display.c) causes the trouble. The first conversion after the launch of the application works fine, the following outputs text that is in no relation to the source value.
The console output (UX_StdLib.cp) works as in the postfix version. When using the FormatX2Str, the output text is always twice the source value, but the code generating the text view of the stored code is all right.
Precautions
So far I have only taken time to test the correct parsing of code and no time testing the software with syntax errors in the input code. Even if in a last update I improved the syntax checking, I can give no guarantee that wrong syntax (or missing compiler switch definition) will not lead to erroneous code potentially with no error message, or that error messages will always state clearly what's wrong.
Moreover this is a beta software. The syntax checking needs to be improved, especially the object oriented version. Also do not forget to define the necessary compiler switches when compiling. I have only tested the code with the compiler switches defined to include all the code control structures. I didn't cheek the combinations.
For the Postfix Notation or Reverse Polish Notation version, when a syntax error is found, the so far generated code is replaced by code that produces a a NAN (Not A Number see IEEE floating point standard) value on the argument stack. The safest way to proceed would be to stop the parsing of the remaining input formula.
For the object oriented version, the routines return a pointer to an instance or kind of "error object" that returns a NAN (Not A Number see IEEE floating point standard) value that will propagate and produce an end value of NAN so the error is noticed and the software does not crash.
I have only tested under MacOS classic. On this system the lines in the text files are ended with a carriage return character (\r). On Unix it is a newline character (\n) and on Windows a \n\r. This may require adaptations.
The use of the scanf routine can also cause some problems. To validate the typed input, return must be typed. When debugging, I noticed that the \r character remained in the buffer and the next call to gets read it out, leading to unexpected behaviour.
On MacOS, if the input text file is opened for example in TextEdit, the application can't open the file and you get an alert at start.
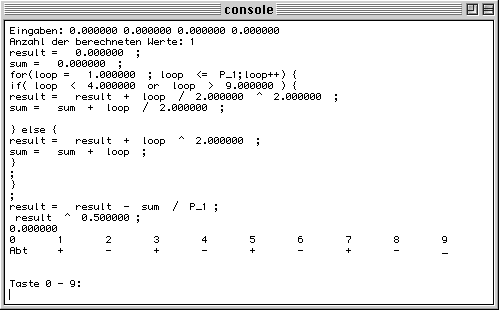
All variables are of type floating point. When doing comparisons, rounding effects may occur. For example, when implementing loops in the usual way may not work exactly as expected:
for (idx=0; idx<10;idx++)
because the test idx<10 may be affected by rounding effects.
To make sure that for this example the loop is executed exactly 10 times:
for (idx = 0; idx<9.9; idx++) -> 0 1 2 3 4 . . . 9 => 10 loops
for (idx = -0.1; idx<10; idx++) -> -0.1 0.9 1.9 2.9 3.9 . . . 9.9 => 10 loops
The same precautions will apply to while and do while loops as well as if statements.
There are also several limitations
Size limitations:
-
RPN / Objects C++: each formula is copied into a buffer whose size is 1400 bytes (hardcoded).
-
Objects C++: the temporary buffer to store the variables during parsing a formula is 50 elements (hardcoded).
-
RPN: the temporary buffer used to store operands in order to set them in priority order is 200 (hardcoded).
Some future updates:
-
The maximum number of formulas that can be stored is given a macro in file Parser.h
#define MAXGRAPHS 30
In future this will be read from the text input file.
-
The same applies to the number of input parameters accessed by p_x.
- RPN: the number is given by a macro defined in Calculs.h
#define MAX_PARAM 10
- Objects C++: the number is given by a macro defined in Parser.h
#define MAX_PARAM 10
-
- Handling of syntax error. In case of functionality that is not activated by a compiler switch (as control structures: if else, for and while) try to skip them.
-
- For postfix notation version: modification of the parsing routines to allow any condition and loop code (instead of simple conparison and inc/decrementation as now).
Updates
The revision history is given in Updates
Other informations
An up to date Browser for MacOS classic is Classilla home page
Other code/applications can be found here:
Other
Contact and legal information Info Mail
Impressum